So you have secured data 🎉 for your model and trained it with model.train, and maybe you have evaluated its performance on a hold-out test set or potentially done an A/B-test. However, how do you know that your model will work, when deployed? Can you ensure that your model still works after some slight changes in input data?
In this article we will cover some considerations for how you can test your ML system to mitigate and take any relevant actions before and after you have deployed your model.
This post has been inspired by some previous work such as:
Also check my GitHub repository for some examples of the tests described below.
What is an ML system?
Note
…The algorithm is only a small part of an ML system in production. The system also includes the business requirements…the interface where users and developers interact…the data stack, and the logic for developing, monitoring & updating your models, as well as the infrastructure. — Chip Hueyn1
-
The above quote is excerpted from Huyen, C. (2022). Designing machine learning systems. ↩︎
The image below shows a high-level overview of what a ML-system is:
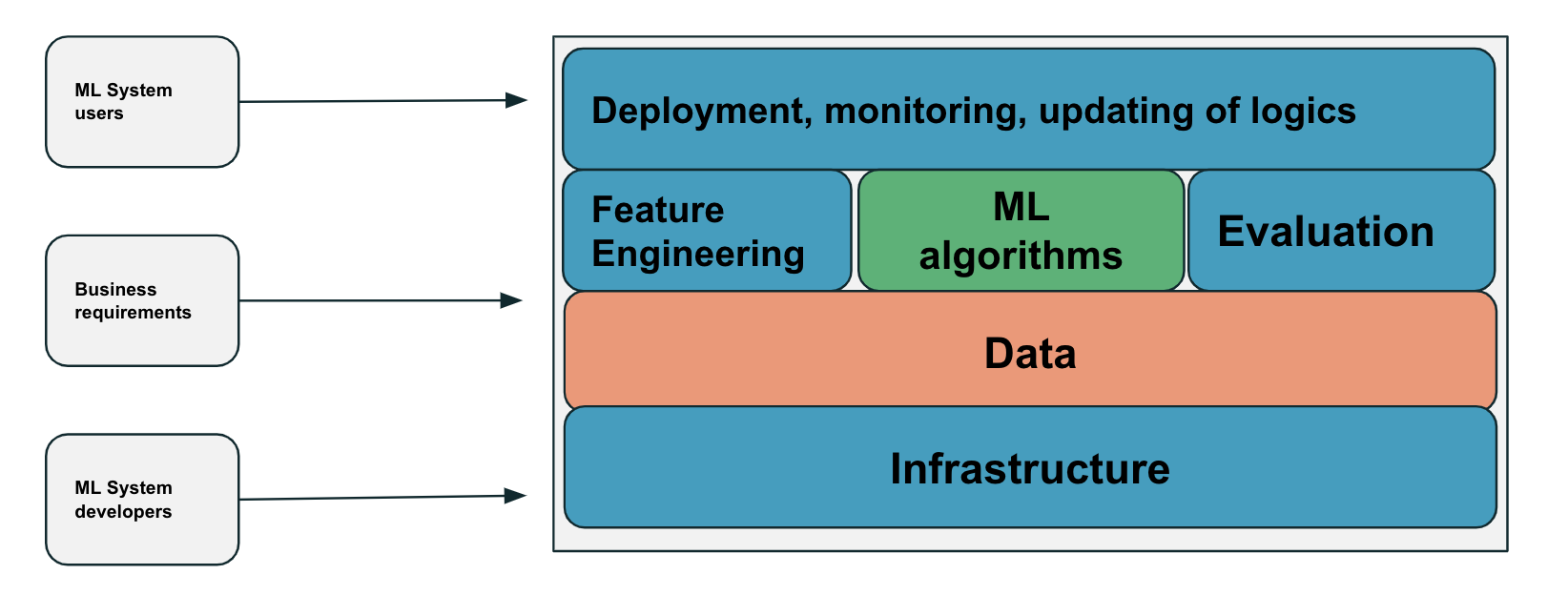
Starting with the input part of the system, one can see the following components:
- ML System users: this can be both external and internal such as end-users or internal teams or other ML systems.
- Business Requirements: depending on the company this might be coming from a product manager, business translator or other internal stakeholders as e.g. marketing.
- ML System developers: different roles such as ML Engineer, AI Engineer, Data Scientist, Data Engineer or Software Developer.
As popularized by Google in their 2015 paper Hidden Technical Debt in Machine Learning Systems the actual ML algorithm is a quite small component of the entire system. You may have heard that data scientists tend to spend >= 20% of their time on actual modelling, and <= 80% of their time on other activities such as cleaning of data. This of course varies between different companies, but I have rarely worked at places where modelling has been 100% of my focus.
Looking inside the “box” of a ML-system infrastructure, data, feature engineering, evaluation and deployment are all vital components, especially when going from experimentation all the way to production. This is probably one of the reasons why ML Engineering has been so popular in the recent years. In my experience the end-to-end (E2E) system design should be thought of already in the earlier stages of developing a ML system to ensure success of a ML powered project or product.
On another note, here we use the term ML System but you might have also heard data product:
Note
Some might see a ML system as a form of data product. There are many other examples (data source, a table, dashboard, etc) but key thing here, is data which is an important component to building the product experience.
In my experience talking purely about the deployed ML model some of these components are important to include in your testing scope:
- Data
- Feature Engineering
- Evaluation
- ML algorithm
However, best practice is to test as much as you can e.g. test-driven development or eval-driven development.
Why test a ML system?
By design ML systems and ML algorithms are non-deterministic and depending on the algorithm you choice it might be hard to exactly understand the inner workings (i.e. white-box vs black-box approaches). An ML system is not better then what data we feed to it i.e. Garbage in Garbage Out (GIGO), and data we use tend to be biased in some way or form.
Also with the advent of Large Language Models (LLMs) which is making the access to and development of ML powered systems accessible to anyone with API calling skills. Testing and making sure that such a system works (one common problem for LLMs is e.g. hallucinations), is imperative.
Testing a ML system vs testing a traditional software system
The image below shows some key difference between a traditional software system (SW), what some might call software 1.0 and a Machine Learning (ML) powered system, what some would call software 2.0:
- In a traditional SW system data together with logic is used as input to produce a desired behaviour.
- In a ML system data together with desired behaviour is used as input to produce some logic.
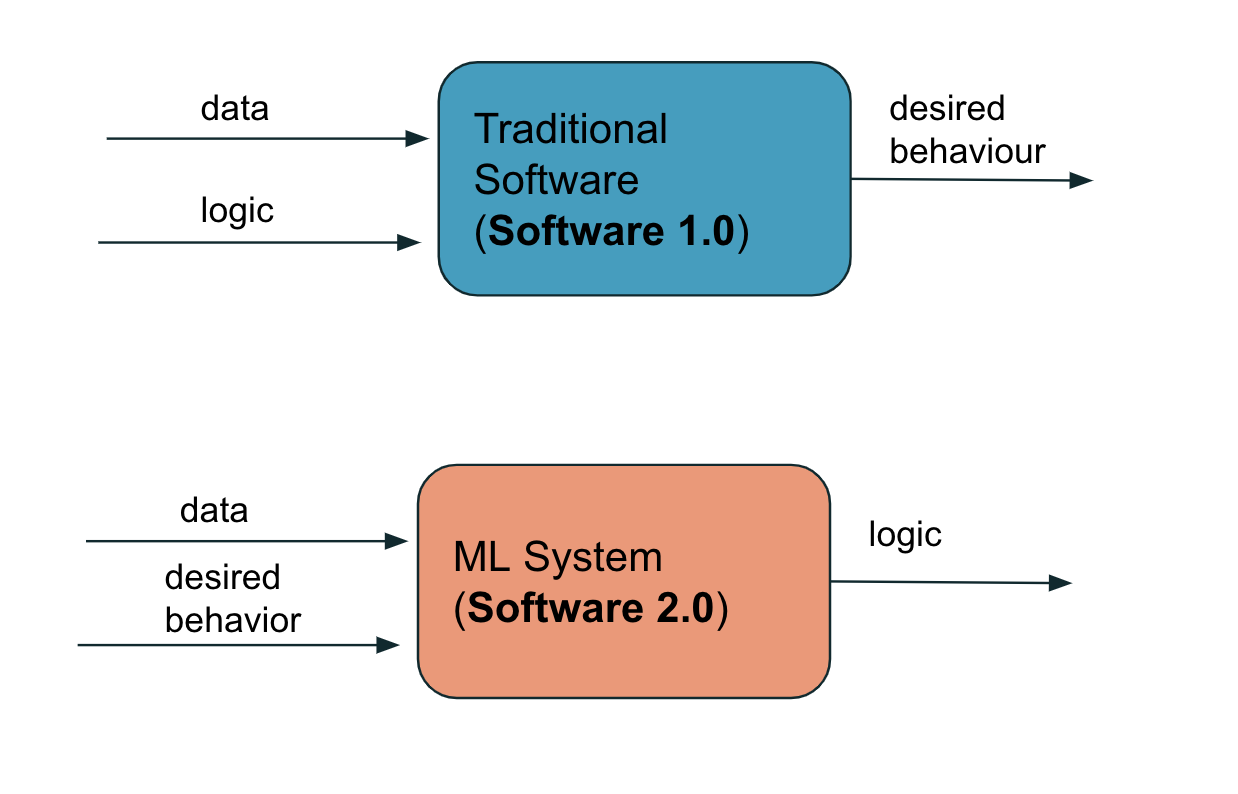
The relationship between input and output for (1) and (2) are sort of flipped. For (1) we need tests to ensure that our written logic manages to produce the actual expected behaviour i.e. a button will always get a certain color on a website regardless of the input. Whilst for (2) we try to encode certain behaviour in the training dataset used to train the model e.g. customers that would churn in a campaign or not, in order to build a system that “learns” what logic it should apply to find customers with a risk of churning.
For a system of type (1) above testing usually boils down to:
- Unit-testing: individual units of source code is tested.
- Regression-testing: tests to make sure the previous fixes to bugs are working.
- Integration-testing: longer tests where the software module is tested E2E with adjacent systems.
- Smoke-testing: testing if a software is stable or not.
- Feature-testing: functional testing of different features in a software.
Note
It is not uncommon that a ML system also have additional SW components for e.g. rules, where some of these tests would also be of importance.
Tests for (2) will be covered in the following sections.
Pre-training test(s)
These type of tests are used as different sanity checks to identify bugs early on in the development process of a ML system. As these tests can be ran without having a trained model, we can use these tests to short-circuit training. Main goal here is to identify errors or bugs to avoid wasting a training job (i.e. cash 💰 & time ⏰).
Some tests that could be good to consider:
Tip
What I have been planning to add as test in the future:
Tip
- Check that one training step of your model reduces the loss
The test above is also a good sanity check step if you are dealing with deep learning models as part of your training process.
Below follows some examples of the mentioned tests:
1import tensorflow as tf
2
3NUM_FEATURES = 10
4NUM_LABELS = 3
5
6def test_model_output_shape(self):
7 """1) Testing that the model output is what we expect"""
8
9 prediction = self.model(self.dummy_data)
10
11 (_, _, output_shape) = prediction.shape
12
13 self.assertEqual(output_shape, NUM_LABELS)
14
15def test_model_input_shape(self):
16 """2) Testing shapes of model input to match NUM_FEATURES""""
17 # get dataset
18 dataset: tf.Dataset = create_dataset(...)
19
20 for features, labels in dataset:
21 actual_shape = features.shape
22 expected_shape = (1, NUM_FEATURES)
23 self.assertEqual(actual_shape, expected_shape)
24
25def test_each_sequence_is_a_unique_user(self):
26 """4) Assertion test for testing that each
27 training sequence is a unique user"""
28 # expected amount of users
29 expected_num_users = 100
30
31 # create dataset
32 dataset: tf.Dataset = create_dataset(...)
33 actual_num_users = len(list(set(dataset.user_id)))
34
35 self.assertEqual(expected_num_users, actual_num_users
36
37def test_no_user_leakage_all_sets_data_split(self):
38 """5) Test to check label leakage between train, test and val sets"""
39 train, test, val = data_split(self.dummy_transactions)
40
41 # get intersection of each set
42 intersection_train_test = set(
43 train["user_id"]
44 ).intersection(set(test["user_id"]))
45 intersection_train_val = set(
46 train["user_id"]
47 ).intersection(set(val["user_id"]))
48 intersection_test_val = set(
49 test["user_id"]
50 ).intersection(set(val["user_id"]))
51
52 # verify that the intersection is equal to the empty set
53 empty_set = set()
54 self.assertEqual(intersection_train_test, empty_set)
55 self.assertEqual(intersection_train_val, empty_set)
56 self.assertEqual(intersection_test_val, empty_set)Post-training test(s)
These type of tests do normally fall into two different groups: invariance tests & directional expectation tests. It is not uncommon that input data might slightly change over time. One example could be income distribution in a country that is changing due to a growing middle class. Other examples are e.g. text data such as transactional descriptions / narratives that are changing with additional or removed keywords. Do also note that for these test to make sense we need an actual trained model.
Invariance test(s)
Real-world data might change due to various reason as we eluded to previously. These test aims to test how stable and consistent the ML model is to perturbations. The logic around these types of tests, can also be applied to training a model which is a form of data augmentation.
Some tests that could be good to consider:
Tip
- Assert that model output consistent to small changes in a feature of interest.
Where you can replace feature with any feature you would like to test e.g. text descriptions, amount, date etc.
To examplify even further, imagine that you have a dataset looking like the below at time t:
| Date | Amount | Description |
|---|---|---|
| 2023-03-15 | 1500 EUR | AirBnB Payment |
| 2023-04-15 | 1500 EUR | AirBnB Payment |
| 2023-05-15 | 1500 EUR | AirBnB Payment |
Then at time time t+1 the dataset looks like the below instead:
| Date | Amount | Description |
|---|---|---|
| 2023-06-05 | 1650 EUR | AirBnB |
| 2023-07-09 | 1700 EUR | AirBnB |
| 2023-08-10 | 1450 EUR | AirBnB |
❓ Do you notice any changes here in the underlying data? This type of behaviour is something we want to test and make sure that our model learns to handle in order to be considered stable and consistent.
Should you test with real data or dummy data? Short answer is that it depends. I have found that faker and factor_boy are some good libraries to generate dummy data for these type of tests:
1import factory
2from dataclasses import dataclass
3from factory import Factory, Faker
4from factory.fuzzy import (
5 FuzzyChoice,
6 FuzzyFloat,
7)
8from typing import Generic, TypeVar
9from dateutil.relativedelta import relativedelta
10
11T = TypeVar("T")
12
13@dataclass
14class DataType:
15 user_id: str
16 date: str
17 amount: float
18 description: str
19 label: int
20
21class BaseFactory(Generic[T], Factory):
22 # Base class to enable typing o .create() method
23 @classmethod
24 def create(cls, **kwargs) -> T:
25 return super().create(**kwargs)
26
27
28class DataTypeFakeFactory(BaseFactory[DataType]):
29 class Meta:
30 model = Transaction
31
32 user_id = Faker("uuid4")
33 date = Faker("date_between", start_date="-1y")
34 amount = FuzzyFloat(100, 2000)
35 description = Faker("sentence")
36 label = FuzzyChoice([0, 1])
37
38class AmountInvarianceFakeFactory(DataTypeFakeFactory):
39 description = "AirBnB"
40 amount = FuzzyFloat(1500, 1700)
41 date = factory.Sequence(
42 lambda x: datetime.date(2023, 1, 15) + relativedelta(months=x)
43 )
44 label = 1pd.DataFrame object and feed it through your feature engineering pipeline for the test:
1def test_amount_invariance(self):
2 """1) Example of invariance test using AmountInvarianceFakeFactory"""
3 # create dummy data
4 dummy_data = AmountInvarianceFakeFactory.create_batch(100)
5 number_of_records = len(dummy_data)
6 df = pd.DataFrame(data=dummy_data)
7
8 # extract features and labels
9 features, labels = create_dataset(df, ...)
10 predictions = self.model.predict(features)
11 nbr_correct = number_correct_predictions(predictions, labels)
12
13 self.assertAlmostEqual(
14 nbr_correct,
15 number_of_records,
16 msg="Different predictions!",
17 delta=0.95 * number_of_records
18 )assertAlmostEqual here in the test and allow a deviance of 5% in predictions in this example. If we would not do so, you would see some flaky failed builds in your CI/CD pipeline 🛠.
Directional Expectations test(s)
Similar to the previous section, these type of tests allows us to define a set of perturbations to the model input which should have a predictable effect on the model output. Meaning that we would only vary a feature of interest, by keeping everything else the same. Similar to what you would do with e.g. a partial dependency plot but applied to testing. The logic around these types of tests, can also be applied to training a model which is a form of data augmentation.
Some tests that could be good to consider:
Tip
- Assert that model output is similar by increasing a certain feature of interest, whilst keeping all other features constant.
- Assert that model output is similar by decreasing a certain feature of interest, whilst keeping all other features constant.
Note the use of similar above, as we cannot guarantee that the model output will be 100% equal in these case. Instead, one needs to operate on a range of allowable threhsolds e.g. 1-3 standard deviation from the mean or +/- 2,5 p.p. as examples. What you should set as good threhsolds depends on your use case and data.
We build another DataTypeFakeFactory for the directional expectations test:
1class IncreasingAmountFakeFactory(DataTypeFakeFactory):
2 """Similar to the invariance test, we can define an increasing amount factory to test here"""
3 description = FuzzyChoice(["AirBnB", "AirBnB Payment"])
4 label = 1
5 amount = factory.Sequence(lambda x: 1500 + 50 * x)
6 date = factory.Sequence(
7 lambda x: datetime.date(2023, 1, 15) + relativedelta(months=x)
8 )We can now build the test using the IncreasingAmountFakeFactory:
1def test_increasing_amount_directional_expectations(self):
2 """1) Example of directional expectations test using IncreasingAmountFakeFactory"""
3 # create dummy data
4 dummy_data = IncreasingAmountFakeFactory.create_batch(100)
5 number_of_records = len(dummy_data)
6 df = pd.DataFrame(data=dummy_data)
7
8 # extract features and labels
9 features, labels = create_dataset(df, ...)
10 predictions = self.model.predict(features)
11 nbr_correct = number_correct_predictions(predictions, labels)
12
13 self.assertAlmostEqual(
14 nbr_correct,
15 number_of_records,
16 msg="Different predictions!",
17 delta=0.95 * number_of_records
18 )Data-drift test(s)
In a real-world setting input data and model output will change (it is not stationary), the image below shows an example of drift in income distribution:
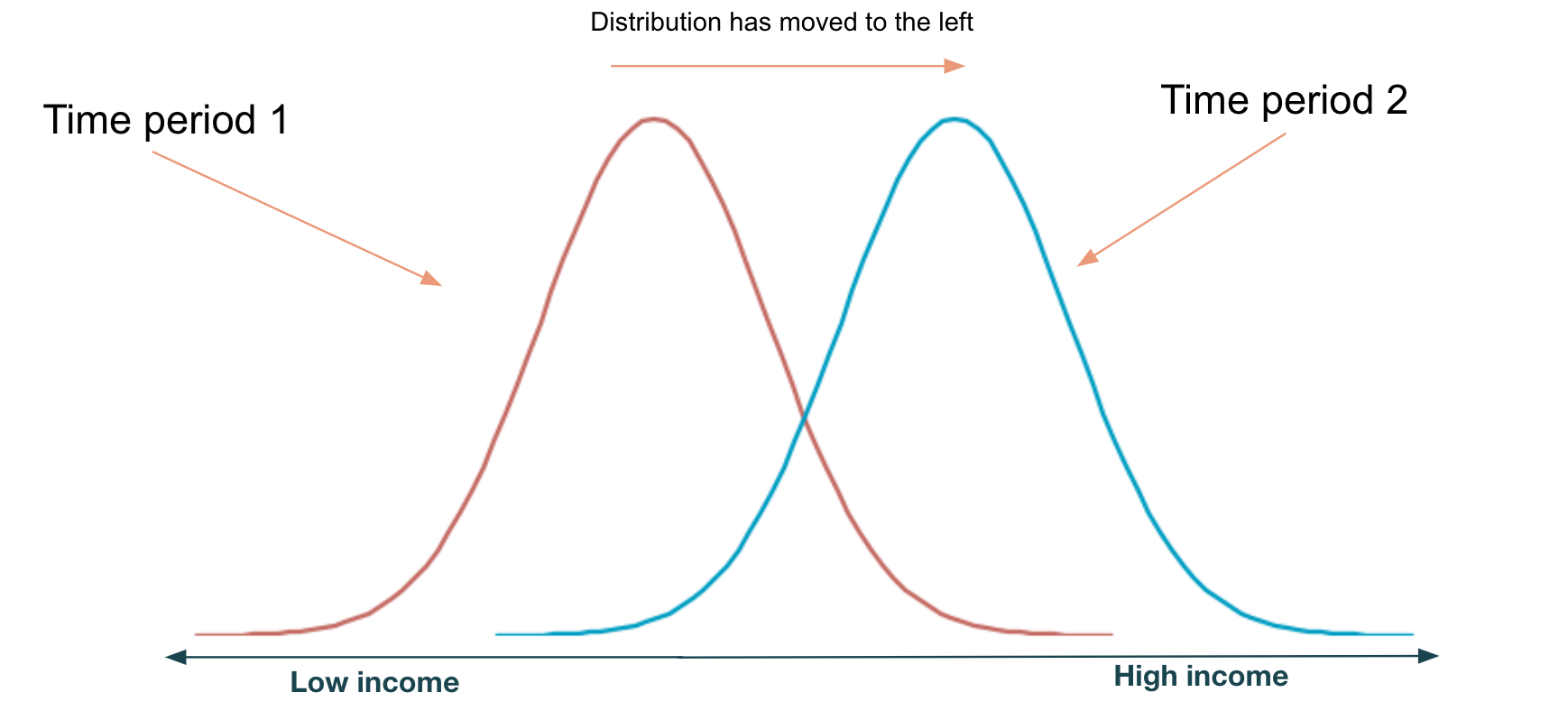
Drift for a given input dataset and model output can be due to many various reasons:
Note
- Bugs in production or ML code.
- Changes or failures in upstream dependencies such as data producer used to create a dataset, modified schema, missing data etc.
- Changes created by the introduction of a ML model, in e.g. targeted marketing with propensity modelling you may effect the actions of person to do something they would not normally do (also called degenerative feedback loops).
- Production data is different from what was used during training.
- Unknown or not handled edge-cases or outliers such as the recent COVID-19 pandemic, i.e. it is probably not normal for people to be hoarding toilet paper.
Due to the cases above we need ways of identifying when data is drifting between time periods t and t+1, to take any appropriate actions such as:
- Re-training the model or models
- Adding static rules for handling of edge-cases
- Collecting more data to make the sample more representative.
Some tests that could be good to consider:
Tip
- Test that the distribution of a certain feature has not changed too much over two time periods.
You can replace feature with any feature of interest but do note, that we use test and too much above. This as what it normally boils down to is to evaluate via statistical tests if there has been any significant difference in the underlying distribution of the input data or the model predictions. Albi Detect maintend by the company Seldon has a quite nice list of drift detection methods.
What I have used before in these scenarios:
Tip
- T-test
- Kolmogorov-Smirnov test
- Kullback–Leibler divergence
With a null hypotehsis threshold of 0.025 - 0.05 depending on the dataset. Sometimes you may have to use higher thresholds.
Example below on how a KS-test could be used as a test, for testing if the mean distribution has changed:
1from scipy import stats
2
3def is_drifting_distribution(self, df, type="mean"):
4 # Performs Kolmogorov-Smirnov-test on the amount distribution
5 distribution_a, distribution_b = self.data.get_amount_distribution(
6 df, test_value=type
7 )
8 test = stats.ks_2samp(distribution_a, distribution_b)
9 return (
10 test.pvalue < self._null_hypothesis_threshold,
11 test.pvalue,
12 test.statistic
13 )
14
15def test_mean_drift(self):
16 # Only perform test if we have enough data
17 if self.data.has_enough_data:
18 for dataset in self._data_distributions.keys():
19 df = self._data_distributions[dataset]
20 ks_drift, ks_pvalue, ks_stat = self.is_drifting_distribution(df)
21 self.assertFalse(
22 ks_drift
23 )
24 self.assertTrue(True)In the examples below, you can of course replace mean with any other statistical metric such as median, variance etc. The features don’t necessary have to be numerical in order for you to do drift tests. For non-numerical features you need to transform them to a distribution via e.g. binning or creating indicator features. If the drift checks should be alerts in another system or parts of your CI pipeline is up to you, the important take away is that you have a process around it will be alerted either before or after deployment. Preferably both.
Much more can be said about drift-detection that might be a topic for another post in the future.
In the meantime if you are more interested I recommend:
- Chapter 8 of 📖 Designing machine learning systems by Chip Hueyn that provides a good overview.
Wow great job 💪, if you have made it this far after some 14+ minutes. This post turned out to be longer then what I expected. Hopefully you have found something useful in what has worked for me before, plus some inspiration for further resources.
Stay tuned for the coming posts!