Part of the AI Odessy series:
- AI Odyssey February EditionThis post!
The month of February 2024, is soon wrapping up, and boy what a month it has been! In this post, I will introduce a new series called AI Odyssey where I will highlight the top 10 announcements (in my humble opinion) in terms of models, releases, libraries, tools, papers and similar, within the AI, ML and DS space 🤖 that have excited me the most.
Without any inherent order or importance let’s start this post!
1. Google releases Gemini 1.5 Pro
What 🎯
On February, 15th, 2024 Google announced the release of Gemini 1.5 just one week after rolling out Gemini 1.0 Ultra. Gemini 1.5 is a new LLM with some interesting properties:
- Dramatically enhanced performance (according to Google).
- More efficient and comparable to Ultra whilst requiring less computing.
- Based on a Mixture-of-Experts (MoE) architecture1.
- Multi-modal LLM (similar to GPT-4V).
- Improved In-Context learning skills from long prompts, without needing fine-tuning.
- With a standard context window of 128,000 tokens, that can be extended to 1 million tokens.
Let that sink in a bit 1 million tokens which is roughly 700,000+ pages. A “regular” book 📖 has somewhere between 250-300 words per page. This would mean that you can use a book of between 2300+ pages as context to the Gemini 1.5 Pro model.
For instance, you could feed in the entire Lord of the Rings and The Count of Monte Cristo at the same time as both of these books are roughly 1200 pages.
What is further highlighted in Google technical report is:
Gemini 1.5 Pro is built to handle extremely long contexts; it has the ability to recall and reason over fine-grained information from up to at least 10M tokens.
In terms of training the setup seems to be similar to the other Gemini models:
Like Gemini 1.0 Ultra and 1.0 Pro, Gemini 1.5 Pro is trained on multiple 4096-chip pods of Google’s TPUv4 accelerators, distributed across multiple datacenters, and on a variety of multimodal and multilingual data. Our pre-training dataset includes data sourced across many different domains, including web documents and code, and incorporates image, audio, and video content.
Based on its multi-model capabilities Gemini 1.5 Pro manages to learn the Kalamang languages:
Given a reference grammar book and a bilingual wordlist (dictionary), Gemini 1.5 Pro is able to translate from English to Kalamang with similar quality to a human who learned from the same materials.
Finally, in terms of performance, the paper also mentions:
Our extensive evaluations with diagnostic and realistic multi-modal long-context benchmarks show that 1.5 Pro is able to maintain near-perfect recall on multi-modal versions of needle-in-a-haystack (see Section 4.2.1.2) and is able to effectively use its context to retrieve and reason over large amounts of data
I always get a bit skeptical (I guess it is the DS in me) when I hear that metrics are close to 100% or near-perfect as this normally means that you are overfitting or doing something wrong. However, it is still very impressive in comparison to GPT-4V on the same dataset. While be exciting to see more benchmarks on this going forward.
Why it interests me 👀
-
For many people building Generative AI applications, hallucinations are a big issue. What people do to mitigate this is to present more relevant content using e.g. Retrieval Augmented Generation (RAG), using Guardrails or fine-tuning the LLM to make it more domain-specific.
-
Having access to 1M+ context window will for instance open up use cases to reason and ask questions around multiple documents (as there might be some dependency amongst each document).
-
There are also speculations that the pricing of Gemini 1.5 Pro could be potentially 10x cheaper than GPT-42. If that is the case you would get a similar or potentially better performant LLM at the price of or cheaper than gpt-3.5-turbo.
Additional resources 💻
2. Google releases Gemma
What 🎯
On February, 21st, 2024 Google announced the release of Gemma a family of lightweight, Open models also roughly a week after releasing Gemina 1.5 Pro ☝️ .
The Gemma release included the following:
- Gemma 2B & Gemma 7B (great for consumer-size GPU)
- Toolchains for inference and supervised fine-tuning (SFT) across all major frameworks: JAX, PyTorch, and TensorFlow through native Keras 3.0
- Integration into the Hugging Face ecosystem (2 base models & 2 fine-tuned ones)
- The Gemma model architecture is based on the transformer decoder.
Looking at the technical paper Gemma in its base form seems to fair well against Mistral and LLaMa in terms of QA, Reasoning, Math / Science and Coding:
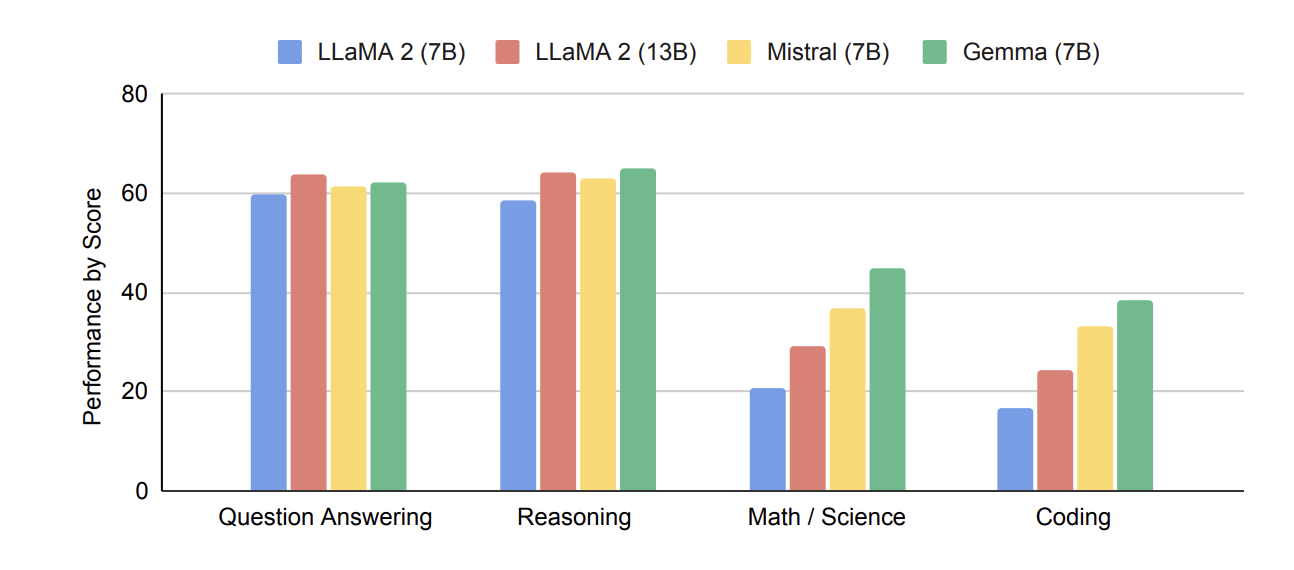
Also looking at the LLM Leaderboard Gemma is ranking highly in comparison to other 7B models. While be interesting to see when we start to see some more fine-tuned versions of Gemma.
Finally, it is also cool to see the quick integration with the Keras library as well where it is as simple as the below to start testing Gemma:
1# load model
2gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
3# generate text
4gemma_lm.generate(What is the meaning of life", max_length=512)Why it interests me 👀
- Fun to see that Google is back on the open models track after releasing Gemini 1.5. Pro, that seems to be very performant.
- It will be interesting to see what other fine-tuned models that will start to pop up in a while.
Additional resources 💻
- Gemma Announcement
- Gemma Technical Report
- Welcome Gemma - Google’s New Open LLM
- Introducing Gemma models in Keras
3. OpenAI releases SORA
What 🎯
On February, 15th, 2024 OpenAI released SORA AI model (text-to-video) that can generate “realistic” and “imaginative” scenes from natural language.
Some properties of SORA:
- Diffusion model jointly trained on videos and images of various lengths, ratios and resolution
- Uses a transformer architecture
- Input data as patches similar to tokens
According to OpenAI:
Sora is able to generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world … Sora serves as a foundation for models that can understand and simulate the real world, a capability we believe will be an important milestone for achieving AGI
Why it interests me 👀
- The demo videos using a fairly simple prompt look very impressive, and I think there are a bunch of use cases for gaming, marketing and filmmaking with something like SORA. After it has been “battle” tested of course.
- The ability to simulate and understand the real world (at least as an initial foundation) is very interesting if and when we do end up with AGI.
Additional resources 💻
4. Predibase announces LoRA Land
What 🎯
On February, 20th, 2024 Predibase announced that they had fine-tuned a bunch of Open-Source LLMs (25 to be exact), based on Mistral. Where these fine-tuned models managed to beat GPT-4 on a couple of benchmarks and domains.
The remarkable thing here, apart from the allegedly high performance, is that the serving of these models all work on a single GPU.
Predibase mentions the following, regarding LoRA 3:
- 25 task-specialized LLMs, and fine-tuned using Predibase
- For a cost of $8.00 on average 💵
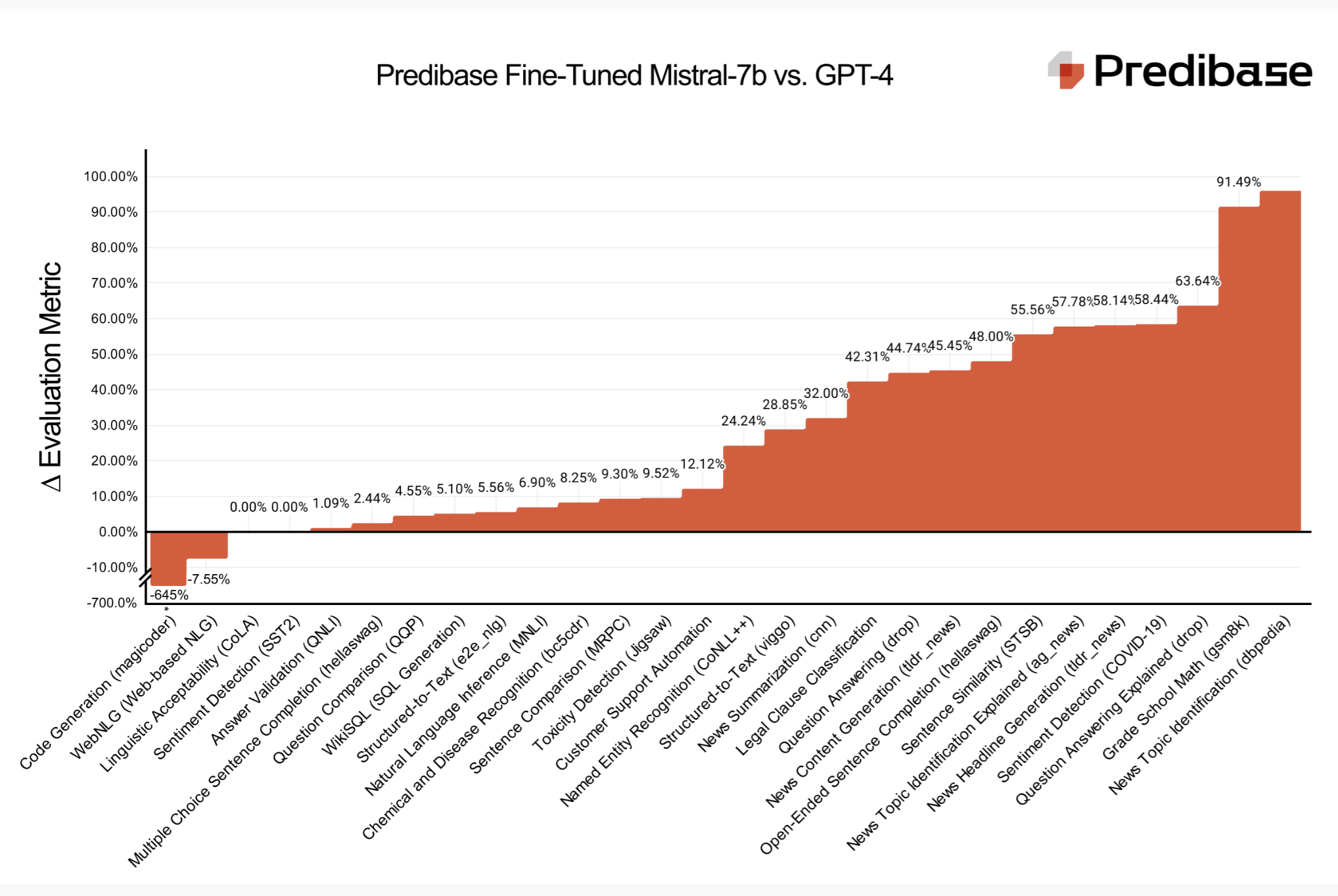
Why it interests me 👀
- You should not sleep on fine-tuning, often a fine-tuned task-specific model can beat a more generalized model, on domain-specific tasks.
- A more cost-efficient way of serving custom LLMs using Predibase, requiring less computing and giving you more control.
Additional resources 💻
- LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4
- LoRA Land
- QLoRA: Efficient Finetuning of Quantized LLMs
5. Stability AI announces Stable Diffusion 3
What 🎯
On February 22nd, 2024 Stability AI announced that they have released (in an early preview) “Stable Diffusion 3”. Like SORA this is a text-to-image model.
What is mentioned in the release:
- Range of models from 800M to 8B parameters
- Combination of diffusion transform architecture and flow matching
No technical report is out yet, but will be interesting to dive deeper when it gets released.
Why it interests me 👀
- For similar reasons as SORA
Additional resources 💻
- Stable Diffusion 3 Annoucment
- Scalable Diffusion Models with Transformers
- Flow Matching for Generative Modelling
6. Astral releases uv uber fast Python packaging
What 🎯
On February, 15th, 2024 the company behind Ruff i.e. Astral released uv. Which is an extremely fast Python package manager and resolver.
See some benchmarks below:

What uv is:
- Extremely fast Python package installer and resolver
- Written in Rust and works as a drop-in replacement of e.g. pip
- Up to 10x faster compared to e.g pip without a caching
- Up to 100x fast compared to e.g. pip with caching
uvcan also be used forvirtualenvironment management- Inspired by Rye.
Why it interests me 👀
- I like the vision of a “Cargo”4 for Python i.e. improve the experience of the somewhat fragmented
Pythonecosystem - Poetry is a great alternative to e.g. Conda or
pipbut it is not perfect - Still early days for
uvbut will definitely try it and see how it takes off
Additional resources 💻
7. Ollama releases OpenAI compatibility
What 🎯
On February, 8th, 2024 the team behind Ollama, announced that Ollama now supports OpenAI Chat Completions API. This also coincided with the announcement from HuggingFace to support the OpenAI Chat completions API. Trying different models both open and closed source, seems to be easier than ever!
An example of how to use this via the OpenAI client is shown below:
1from openai import OpenAI
2
3client = OpenAI(
4 base_url = 'http://localhost:11434/v1',
5 api_key='ollama', # required, but unused
6)
7
8response = client.chat.completions.create(
9 model="llama2",
10 messages=[
11 {"role": "system", "content": "You are a helpful assistant That is an export in human life existential questions."},
12 {"role": "user", "content": "Why is 42 seen as the meaning of life?"},
13 ]
14)
15print(response.choices[0].message.content)Why it interests me 👀
- No need to change how you invoke LLMs whether it be open or closed source.
- Make it easier for ML developers to try different models and parsing results in a similar way.
Additional resources 💻
8. Chain-of-Thought Reasoning Without Prompting
What 🎯
On February, 15th, 2024 researchers from Google Deepminde released a paper called “Chain-of-Thought Reasoning Without Prompting”.
The main thesis is the following:
Can LLMs reason effectively without prompting? And to what extent can they reason? We find that, perhaps surprisingly, there exists a task-agnostic way to elicit CoT reasoning from pre-trained LLMs by simply altering the decoding procedure.!
Illustration of their approach below:
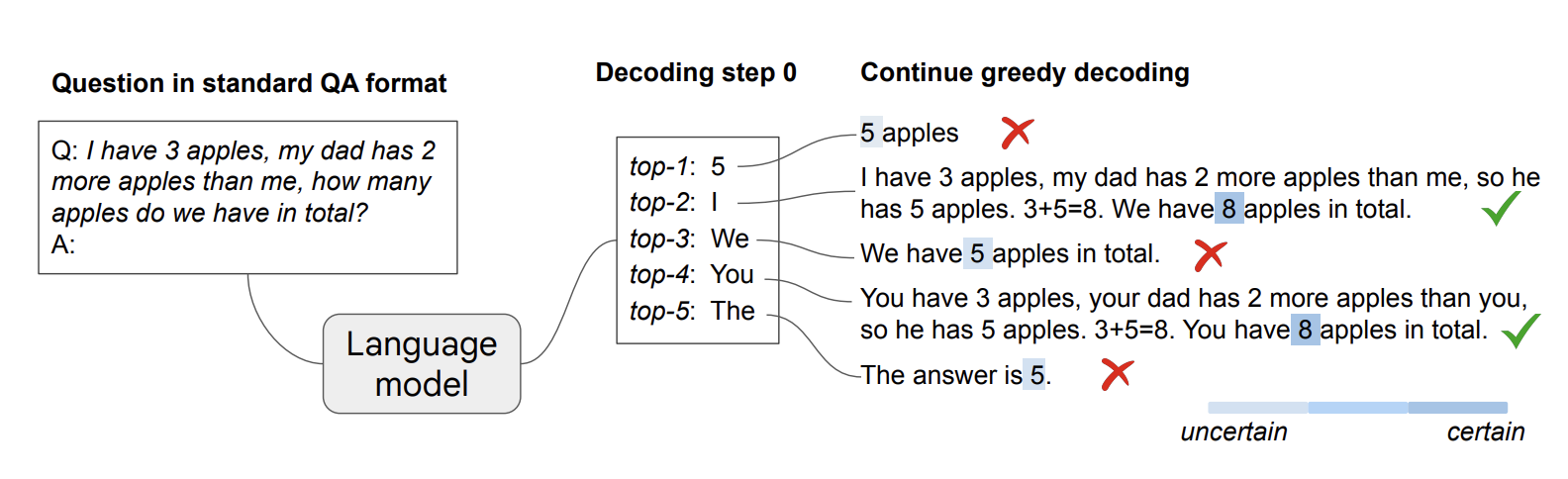
Some initial points from the paper:
- Input is using the standard question-answer (QA) format:
Q:[question]\nA:. - CoT decoding offers an alternative way to elicit reasoning capabilities from pre-trained LLMs without explicit prompting.
- Model demonstrates increased confidence in the final, answer when a CoT reasoning path is present in the decoding process.
It is a sound and interesting approach to focus more on using the “intrinsic” reasoning capabilities of an LLM rather than influencing its reasoning via CoT-prompting.
And some additional points from the paper:
- They also found that higher values of 𝑘 (in terms of top k tokens to do CoT-decoding from) typically result in improved model performance.
- Another noteworthy observation is that CoT-decoding can better reveal what LLMs’ intrinsic strategy in solving a problem, without being influenced by the external prompts which could be biased by the prompt designers.
- Experiments were using PaLM-2 and Mistral-7B.
Why it interests me 👀
- Prompt Engineering sometimes feels more of an art compared to a science where small slight changes can fool an LLM fairly easily.
- Cleaver way of using the intrinsic capabilities of pre-trained LLMs.
- Looking forward to more “clever” ways of pushing accuracy from an LLM without having to too much on prompt engineering.
Additional resources 💻
9. SiloAI completes training of Poro
What 🎯
On February 20th, 2024 Silo AI announced that they have finalized training of their Poro family of models. These models were first announced last year in November.
As mentioned by Silo AI in their post:
The completion of training Poro functions as a proof point for an innovative approach in developing AI models for languages with scarce data resources. Poro outperforms all existing open language models on the Finnish language, including FinGPT, Mistral, Llama, and the BLUUMI 176 billion parameter model, among others.
Some key features of Poro 34B from the post:
- Poro Research Checkpoints will be available
- Poro 34B has 34.2 billion parameters and uses a BLOOM architecture with ALiBi embeddings
- Multilingual capabilities: Poro is designed to process English and Finnish and has proficiency with a variety of programming languages. Additionally, it can perform translation between English and Finnish.
- Open source: Poro is freely available under the Apache 2.0 License
- Training details: Poro is trained using 512 AMD MI250X GPUs on the LUMI supercomputer in Finland.
Why it interests me 👀
- Great seeing that Europe is stepping up its Generative AI game, and the Nordics in particular!
- Interesting training approach with using a “low” resource language such as Finish together with English to derive cross-lingual signals for training. This is likely beneficial for other Nordic languages as well.
- More language-specific models i.e. models for Nordic languages vs General models may be better for certain use cases.
Additional resources 💻
- Europe’s open language model Poro: A milestone for European AI and low-resource languages
- Poro - a family of open models that bring European languages to the frontier
- Europe’s open language model family Poro extends checkpoints, languages and modalities
- Poro Model Card
10. Groq - extremely fast LLM serving using LPUs
What 🎯
On February 20, 2024, I started to hear a lot of buzz connected to the specialized chip manufacturer Groq showcased an impressive 500+ tokens/seconds ratio for serving LLMs. This mainly by using their specialized LPU chips.
An LPU or Language Processing Unit is:
An LPU Inference Engine, with LPU standing for Language Processing Unit™, is a new type of end-to-end processing unit system that provides the fastest inference for computationally intensive applications with a sequential component to them, such as AI language applications (LLMs).
According to Groq their chip overcomes the following challenges, for LLMs:
- Compute density
- Memory bandwidth
When doing a small test it is fast:
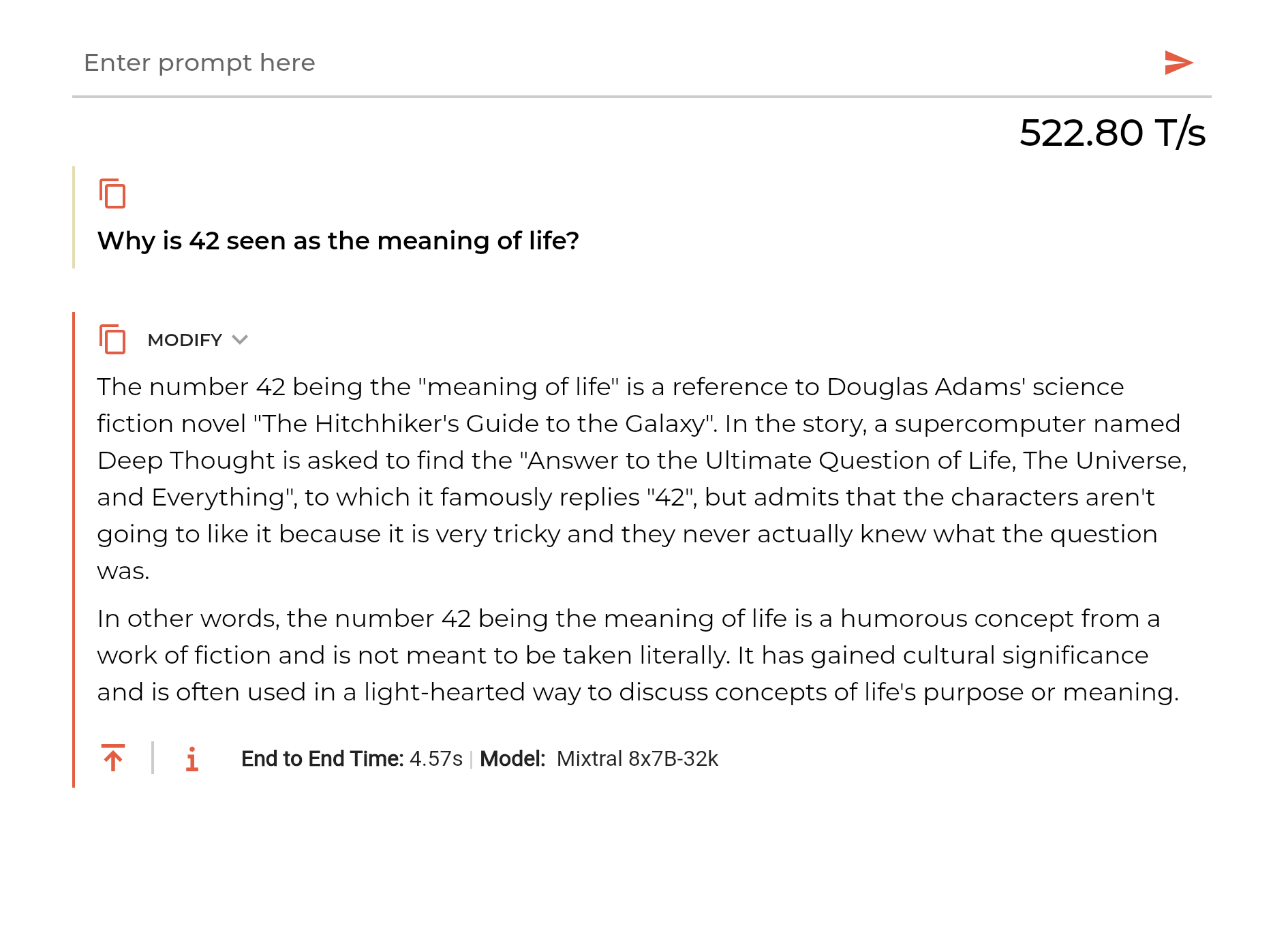
I think it is very interesting to see other more specialized chip providers show up, such as Groq. However, there are also other providers such as graphcore offering IPUs 5.
Why it interests me 👀
Serving both commercial and open LLMs can take quite some time for tricky applications.
- Groq and their LPU chips seem to push boundaries in terms of LLM serving and speed of inference.
- Nice with some alternatives to high-demand GPUs like the A100s and H100s
Additional resources 💻
- Groq Chat
- https://wow.groq.com/artificialanalysis-ai-llm-benchmark-doubles-axis-to-fit-new-groq-lpu-inference-engine-performance-results/
- Groq ISCA Paper 2020
- Groq ISCA 2022 Paper
-
Similar to the Mixtral model launched last year: https://mistral.ai/news/mixtral-of-experts/ ↩︎
-
Low-rank Adapter (LoRA) finetuning is a method that reduces memory requirements by using a small set of trainable parameters, often termed adapters, while not updating the full model parameters that remain fixed. ↩︎
-
Package manager for Rust ↩︎
-
Intelligence Processing Unit (IPU) technology, which is another ML-specialized chip. ↩︎